Visualize the Data
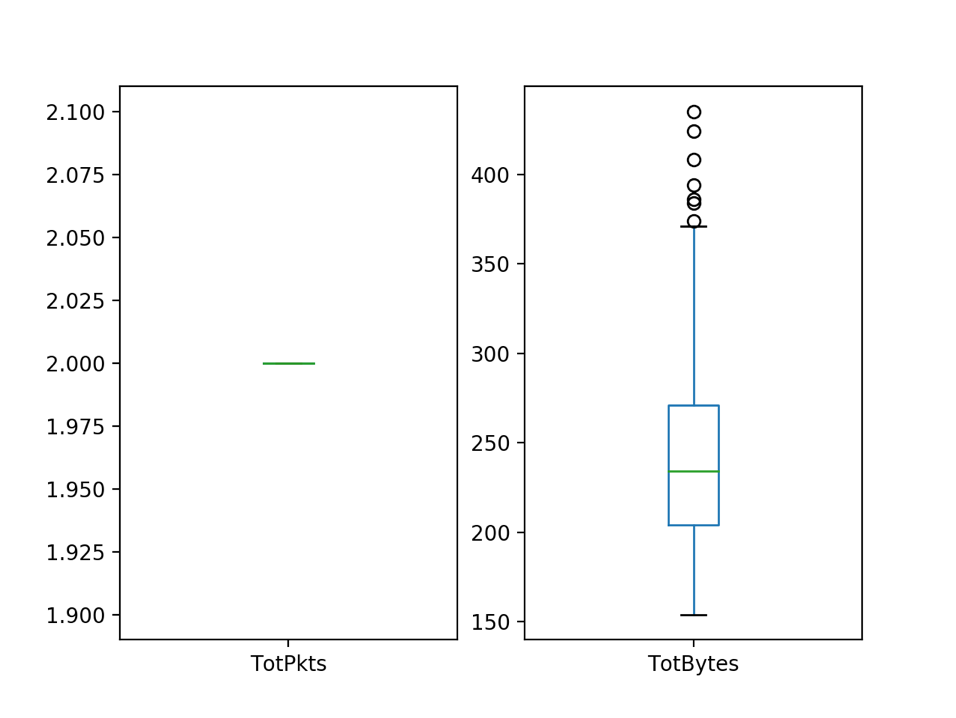
Box and Whisker plots (box plots, for short) are an exploratory visualization technique that show range and distribution of a single variable. The middle line indicates the median of the distribution. The top and bottom sides of the box indicate the 75th and 25th percentiles of the data distribution. And the whiskers show 1.5 times the Interquartile Range (IQR) which is the 75th percentile minus the 25th percentile. Outliers are shown as points outside the whiskers. For DNS queries, flows are limited to two packets (a request and a response), but can vary in the number of bytes in each flow.
## Plot Box Plots
dns = df[df["Dport"] == "53"]
dns[["TotPkts","TotBytes"]].plot(kind='box',subplots=True,layout=(1,2),sharex=False,sharey=False)
plt.show()
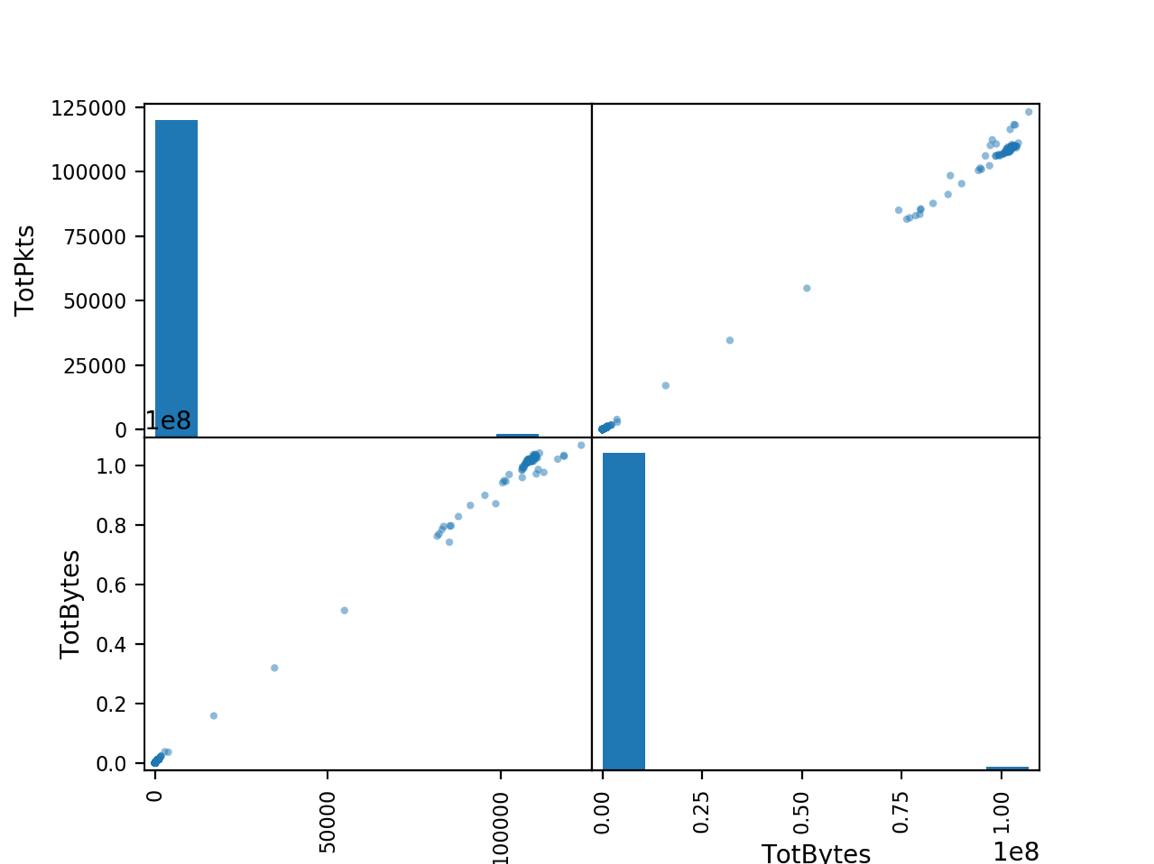
A Scatter matrix is another form of exploratory data visualization that shows the distribution of each variable on the diagonal axis and the correlation between the variables in the off-diagonal spaces. As expected, bytes and packets for a flow are highly correlated.
## Plot a Scatter Matrix
scatter_matrix(df[["TotPkts", "TotBytes"]])
plt.show()